Proses ”Pemerolehan Bahasa” Kecerdasan Buatan
Bukan tidak mungkin kemampuan kognitif manusia akan semakin berkurang karena tingkat ketergantungan yang semakin tinggi pada kecerdasan buatan. Bahkan untuk sekadar mengutarakan pendapatnya.

Kecerdasan buatan
Syahdan, dahulu kala, ketika ponsel masih sekadar untuk menelepon dan mengirimkan pesan pendek atau SMS, rasanya tidak mungkin kita dapat menikmati canggihnya teknologi kebahasaan seperti sekarang. Teknologi kebahasaan ini berkembang pesat dengan hadirnya kecerdasan buatan berbasis teks, salah satu pengembangan dari artificial intelligence (AI).
Terima kasih layak kita berikan kepada para ilmuwan komputer, ahli bahasa, dan mereka yang secara mendalam mempelajari cara kerja otak manusia. Mereka berjibaku menemukan cara mendidik sebuah model mesin agar dapat mandiri mempelajari pola dan aturan bahasa manusia.
Dahulu, rasanya tidak mungkin sebuah mesin dapat mengenali bunyi ucapan bahasa manusia meskipun sebatas sebuah kata. Kini?
Dalam sistem kecerdasan buatan berbasis teks, mesin diajari memahami bahasa manusia. Dalam hal ini termasuk tata bahasa, sintaksis, semantik, dan pragmatik. Sistem ini membaca teks dalam bentuk dokumen, percakapan, pesan teks, buku, dan artikel di internet, sebagai sebuah data.
Hal itu dilakukan untuk ”menggali” informasi yang kemudian akan diolah dan disajikan sebagai jawaban pertanyaan yang diajukan penggunanya. Akurasi jawaban ditentukan oleh masukan berupa teks dari pengguna serta algoritma pemrograman. Mesin pencari Google adalah salah satu contoh sistem yang mampu memahami bahasa manusia hingga tataran semantik, baik lisan maupun tulisan.
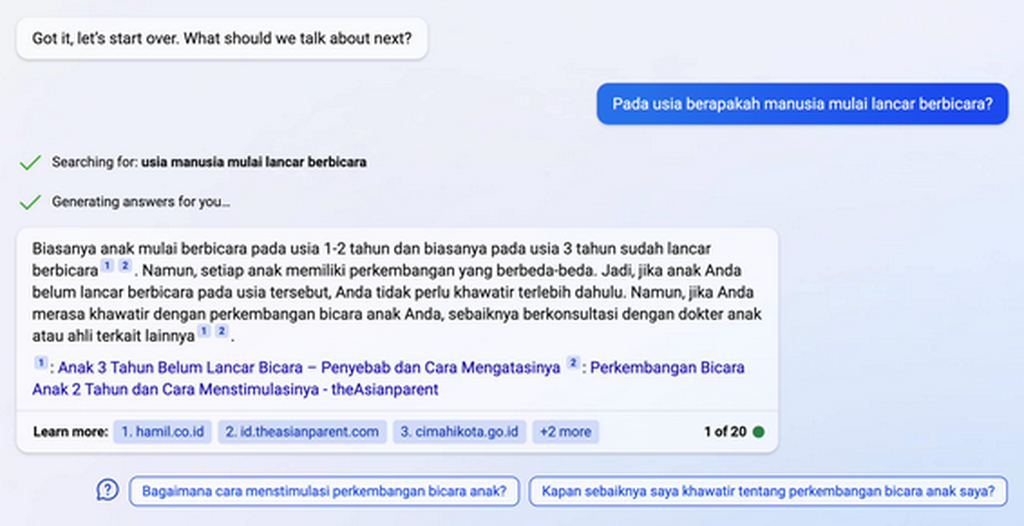
Berikut adalah contoh bagaimana kecerdasan buatan berbasis teks mampu memberikan respons atas sebuah pertanyaan hanya dalam hitungan detik dan menyajikannya dalam bahasa asli si penanya. Terdapat dua versi jawaban sebagai contoh.
Pertama adalah jawaban dari ChatGPT-3.5 murni, besutan OpenAI. Sementara gambar kedua adalah jawaban dari ChatGPT-4.0 yang penggunaannya telah diselaraskan (fine tuning) untuk mendongkrak kemampuan Bing, mesin pencari bikinan Microsoft.

ChatGPT-3.5 murni diakses dari Chat.openai.com.
ChatGPT-4.0 yang digunakan dalam Bing, mesin pencari buatan Microsoft.
Terlihat bahwa jawaban dari ChatGPT-3.5 lebih panjang karena memberikan beberapa tambahan penjelasan yang dirasa berkorelasi dengan pertanyaan yang diajukan. Terdapat pula kesimpulan dan saran dalam jawabannya. Adapun respons dari ChatGPT-4.0 lebih sedikit meskipun juga dilengkapi kesimpulan dan saran.
Karena APIChatGPT-4.0 ditanamkan di Bing, pengembang Bing pun dapat dengan bebas menambahkan karakter mesin pencari, seperti mengelaborasi jawaban menggunakan pertanyaan lanjutan yang relevan.
Hasilnya kemudian ditawarkan dalam bentuk tautan kepada penanya atau pengguna, alih-alih langsung menjabarkannya dalam sebuah jawaban panjang. API adalah akronim dari application programing interface, yaitu program antarmuka yang dapat menghubungkan antara satu aplikasi dan aplikasi lainnya.
Kemampuan kedua versi kecerdasan buatan tersebut dalam menghasilkan jawaban secara mandiri dalam waktu kurang dari 10 detik sangatlah mencengangkan. Apalagi jawaban itu ditulisdalam bahasa asli si penanya dengan gramatikal yang baik. Ini menunjukkan suatu saat nanti, kecerdasan biologis akan mendapatkan tantangan serius dari kecerdasan digital yang dikembangkan dalam skala masif.
Bukan tidak mungkin kemampuan kognitif manusia akan semakin berkurang karena tingkat ketergantungan yang semakin tinggi pada kecerdasan buatan. Bahkan untuk sekadar mengutarakan pendapatnya, yang notabene membutuhkan proses di otak sebelum keluar menjadi sebuah karya tulis ataupun pendapat secara lisan.
Ini bukan ketakutan tanpa dasar meskipun sistem kecerdasan buatan itu sendiri menolak dikatakan mampu menggantikan fungsi kognitif manusia, setidaknya untuk saat ini, seperti terbaca dalam jawaban dari ChatGPT-3.5 berikut ini.

ChatGPT-3.5 murni diakses dari Chat.openai.com.
Dari jawaban di atas terlihat bahwa kemampuan mesin ini dalam mengenali teks perintah, mengumpulkan informasi relevan yang tersebar, kemudian merangkum dan menyajikannya menjadi sebuah jawaban yang terstruktur dalam waktu singkat, bisa jadi telah melebihi perolehan informasi oleh sistem kecerdasan biologis.
Padahal, sistem kecerdasan biologis memiliki sistem kerja yang jauh lebih kompleks karena tidak jarang juga melibatkan emosi dalam proses menghasilkan jawaban.
Dari beberapa contoh percakapan di atas, menarik untuk melihat bagaimana manusia menemukan cara untuk melatih mesin sehingga mewujud menjadi kecerdasan buatan.
Metode pembelajaran bahasa alami atau natural language processing (NLP), yang digunakan dalam melatih mesin untuk memahami, memproses, dan menghasilkan teks dalam bahasa manusia, menjadi sebuah bidang yang menarik dalam pengembangan kecerdasan buatan.
Langkah-langkah di bawah ini, yang diperoleh dari OpenAI melalui chatbot ChatGPT, mungkin dapat memberikan gambaran tentang proses pembelajaran bahasa alami untuk melatih mesin.
Ketika ditanya dengan input teks ”bagaimana penggunaan NLP dalam pelatihan ChatGPT”, berikut adalah jawabannya:
1. Pengumpulan dan pemrosesan data: data teks dalam (berbagai) bahasa manusia dikumpulkan dari berbagai sumber, seperti buku, artikel, internet, dan percakapan manusia. Data yang dikumpulkan itu kemudian diproses untuk disaring. Data yang tidak relevan dikategorikan sebagai sampah dan dibuang, sedangkan data yang terpilih diformat kembali agar sesuai dengan kebutuhan.
2. Pembentukan korpus: korpus adalah sekumpulan besar teks yang digunakan sebagai data latihan. Data ini kemudian dibagi menjadi potongan yang lebih kecil untuk digunakan selama proses pelatihan.
3. Tokenisasi: teks yang terdapat dalam korpus dipisahkan menjadi unit-unit terkecil yang disebut token. Tokenisasi melibatkan pemisahan kata-kata, frasa, atau tanda baca agar dapat diolah oleh model.
4. Pelatihan model: proses pelatihan melibatkan penggunaan teknik pembelajaran mesin, seperti deep learning (sistem yang memungkinkan kecerdasan buatan belajar dari pengalaman, seperti layaknya manusia).
5. Model seperti ChatGPT menggunakan neural network (dalam khazanah kecerdasan buatan, secara sederhana dapat dikatakan bahwa neural network adalah sebuah sistem yang menyerupai otak manusia dalam hal memproses dan mempelajari informasi) untuk mempelajari pola-pola dalam data latihan. Dalam pelatihan, model diberikan input berupa token dan ditugasi memprediksi token selanjutnya dalam urutan teks.
6. Optimalisasi dan penyetelan: setelah pelatihan awal, model dievaluasi dan dianalisis untuk melihat bagaimana kinerjanya. Jika diperlukan, penyetelan tambahan atau pengoptimalan dilakukan untuk meningkatkan kualitas respons yang dihasilkan.
Membaca jawaban dari ChatGPT di atas, penulis teringat ketika mendapat tugas untuk mengelompokkan kata dalam bahasa Indonesia berdasarkan kelas kata. Keperluannya, untuk membuat mesin pencari internal di lingkungan perusahaan.
Pengelompokan kata itu bertujuan untuk membuat data set yang akan digunakan untuk melatih mesin pencari menggunakan algoritma yang telah dipersiapkan. Mungkin kira-kira seperti itulah proses ”pelatihan berbahasa” bagi kecerdasan buatan.
Karena sejumlah bahasa memiliki pola dasar pembentukan yang mirip, ChatGPT dapat dengan mudah mempelajari dan menguasai bahasa-bahasa yang populer digunakan, seperti bahasa Inggris, Indonesia, Perancis, dan Spanyol.
Tangkapan layar jawaban dari ChatGPT di bawah ini mungkin dapat menjadi bukti bahwa pelatihan menggunakan sejumlah langkah di atas memungkinkan chatbot ini menjadi semakin baik hari demi hari.

ChatGPT-3.5 murni diakses dari Chat.openai.com.
Dibutuhkan intervensi manusia untuk membuat jawaban di atas menjadi lebih akurat, tidak berpanjang lebar, serta tidak sekadar merangkum atau memadupadankan jutaan teks, yang tersedia sebagai data, dengan algoritma pemrograman.
Melatih kecerdasan buatan memakai teknik supervised dan reinforcement learningadalah sedikit dari banyak cara yang bisa terus dikembangkan. Teknik ini adalah model pelatihan yang telah digunakan untuk melatih ChatGPT-4.0 dengan campur tangan manusia di dalamnya,
Untuk itu, terdapat tombol upvote dan downvote di sebelah kanan kotak jawaban. Pengguna dapat memberikan penilaian terhadap respons dari ChatGPT sebagai umpan balik. Data yang diperoleh dari umpan balik pengguna akan semakin mendongkrak pemerolehan bahasa mesin kecerdasan buatan.
Dari beberapa tangkapan layar di atas, tampak bahwa mesin kecerdasan buatan telah mampu memahami pertanyaan (informasi berupa data berbentuk teks) yang disodorkan oleh pengguna.
Dalam konteks pemrosesan bahasa alami menggunakan komputer, pemahaman tersebut mengacu pada kemampuan untuk memahami dan menafsirkan teks ataupun ucapan manusia.
Lalu, bagaimana dengan akal sehat? Meski pemahaman dan akal sehat adalah dua hal yang berkelindan, apakah kecerdasan buatan telah mencapai tataran ini? Atau, akankah suatu saat nanti?
Teguh Candra, Penyelaras Bahasa Kompas